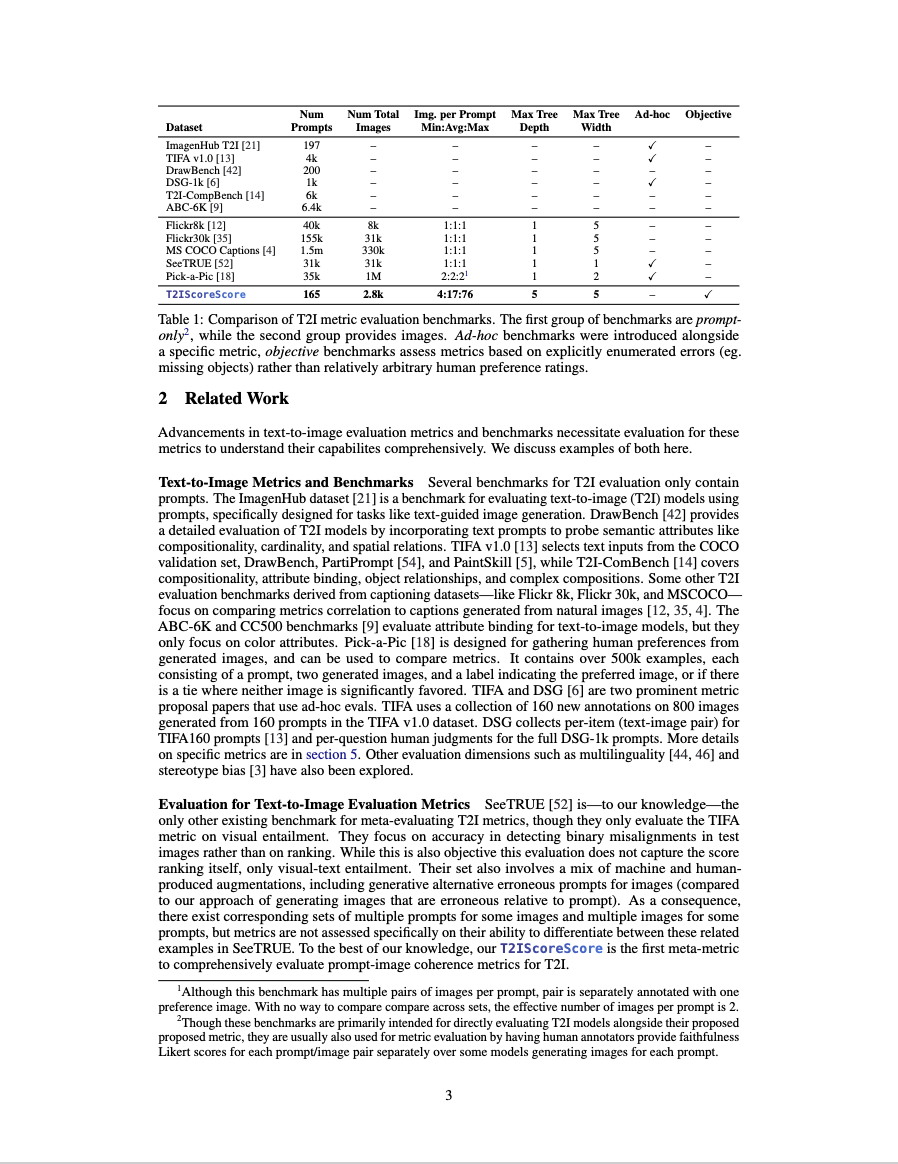
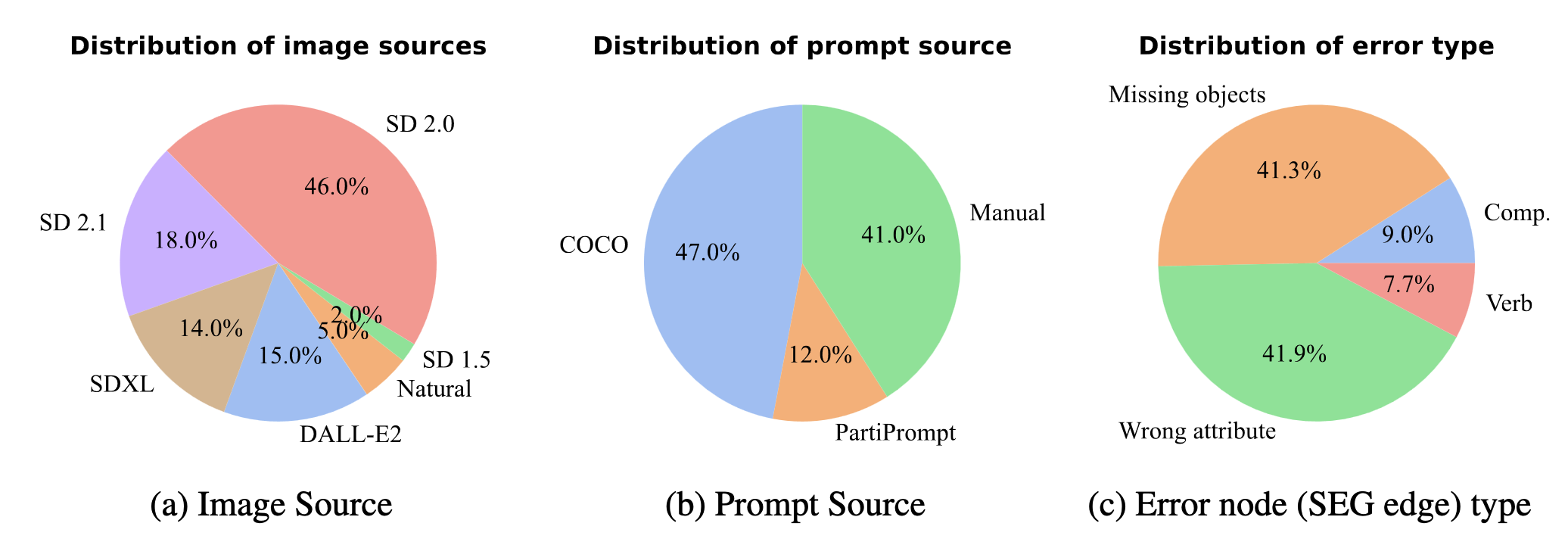
Images in TS2 are collected from a variety of sources, including multiple Stable Diffusion variants, DALL-E 2, and the free stock image website Pexels.
Prompts that weren't hand-written were sampled from MS COCO and PartiPrompts.
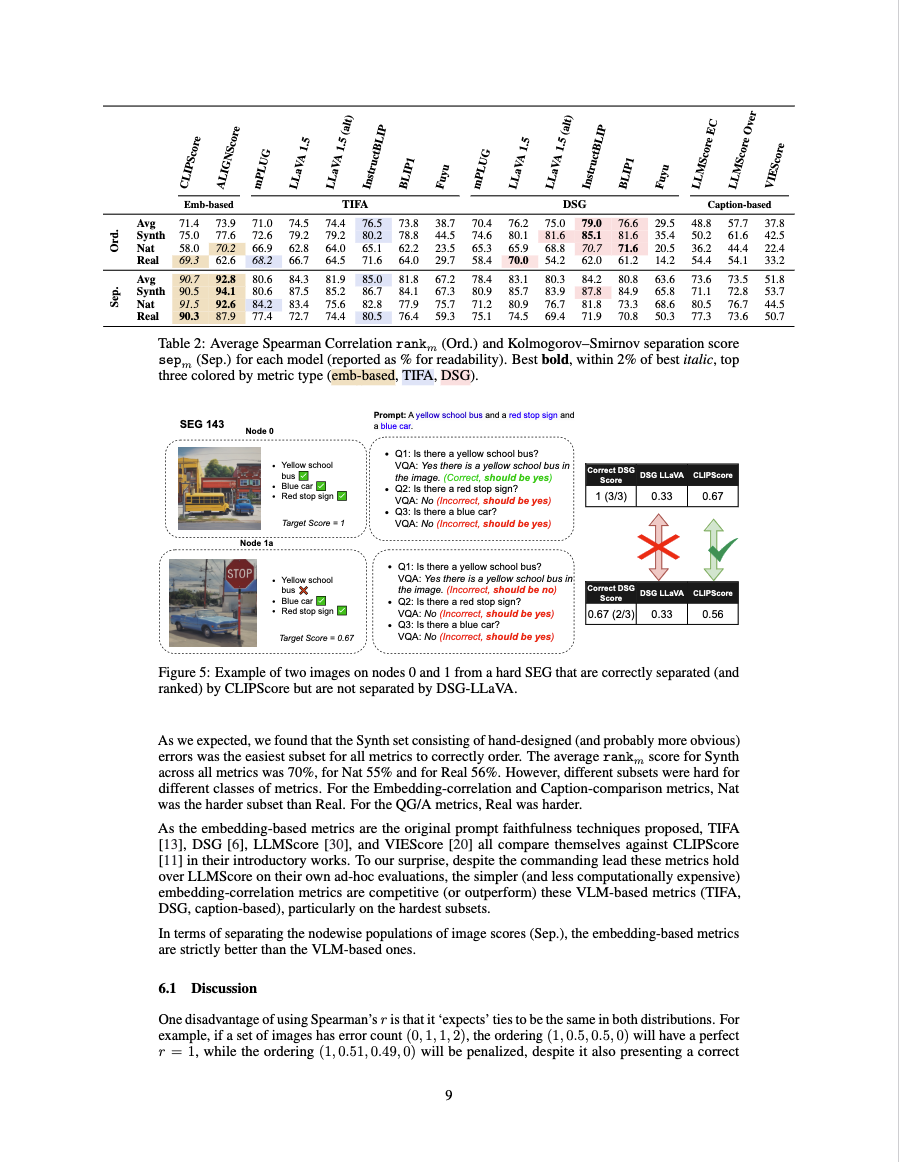
The SEGs contain a variety of errors, including missing objects, incorrect object properties, composition errors, and verb errors. SEG distributions depicted:
As mentioned above, TS2 contains three partitions of SEGs; Synthetic Errors, Natural Images, and Natural Errors.
They primarily differ in the order in which the images, prompt, and error graph were produced.
For the Synth group of SEGs, from an initial prompt an error graph was designed, and images were generated to fill the nodes in the graph. (left side of below figure).
For the Nat group of SEGs, images were collected from stock photo websites and prompts were designed to place them in a constructed error graph (middle of below figure).
For the Real group of SEGs, a single prompt was used to produce many images, including real T2I generation errors. These were then sorted into an error graph (right of below figure).

 ):
): Co-first authors
Co-first authors
 University of California, Santa Barbara
University of California, Santa Barbara
 Fatima Al-Fihri Predoctoral Fellowship
Fatima Al-Fihri Predoctoral Fellowship